
扫描件转换成word转换器
官方最新版大小:44.41M更新:2025-03-29 19:22
类别:转换翻译系统:Win7, WinAll
分类
大小:44.41M更新:2025-03-29 19:22
类别:转换翻译系统:Win7, WinAll
扫描件转换成word转换器是一款word转换器软件,软件利用OCR识别技术可以轻松的完成大量的工作,只需要将图像格式转化成文本格式。喜欢就赶紧来试用吧!
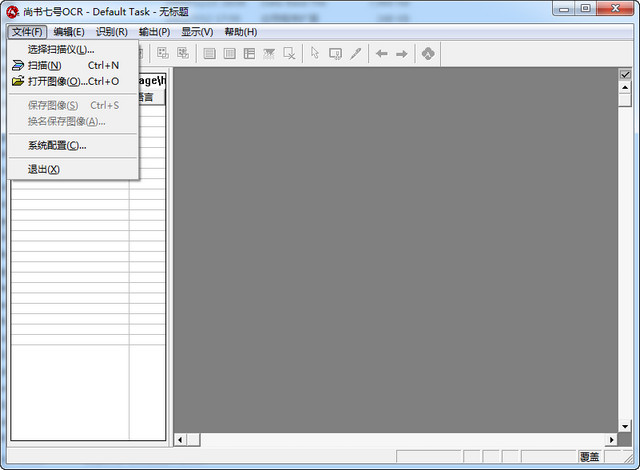
用扫描仪扫描的文字图像,不能对个别文字进行编辑修改,在教学中,需要利用文字识别软件,将文字图像进行识别,将图像格式转化成文本格式,常见的文字识别软件有很多,主要功能基本相同,尚书七号就是其中很优秀的一款。用尚书七号对文字图像识别转化的过程,利用其主菜单:文件、编辑、识别、输出可以很方便地完成。
步骤1:获取文字图像文件。
选择文件菜单下的扫描或打开图像将已经扫描好的图像文件打开)命令,打开图像文件。如果连接了多台扫描仪,可以选择文件菜单下的选择扫描仪命令,调用扫描仪。
步骤2:对扫描的图像页进行调整
选择编辑菜单下图像页面的处理子菜单下的图像页的倾斜校正(提供自动和手动实现方法)及旋转等命令,将扫描的图像页进行调整。
步骤3:版面分析与文字识别转化
版面分析,选择识别范围,在进行文字识别前要选择识别范围,识别过程的核心是版面分析。尚书七号的自动版面分析功能很强,对报纸杂志等复杂的版面,也能保持很高的分析正确率。
设置好后,直接点击开始识别的按钮就可以进行文字识别了。
步骤4:校对修改
自动识别完毕,识别结果的文本窗口会弹出,这个窗口能够提供识别结果的校对,为了校对方便,尚书七号增加了光标跟随显示原图像行的校对方法(如图3出现的黄色提示行的出现)。
提供的校对方法,一眼就能够看到图像原文和识别出文本的差别,如果发现识别有误,可以进行修改。
步骤5:输出
如果检查修改后确认无误,选择识别结果的输出菜单,输出的文件格式有:RTF、HTML、XLS、2126,可以根据自己的需要选择对应的格式。如果用户想得到类似原文的识别结果,请选择RTF格式。把RTF格式输出的文件用WORD打开后,会发现几乎保留了原文的所有痕迹,包括原来页面中的彩色图像,都已经保留在WORD中了。

1、图片质量。批量识别时,首先应确保要识别的图片质量。如不能识别还需要重新处理,甚至会导致软件死掉,浪费时间。我本人就曾深受其苦。图片分辨率应稍高,肉眼看感觉偏大,因为识别工具是有点近视的,文字和底色对比要求不高,通常来说,肉眼能看清楚即可,底色发灰或发黑基本不会影响识别结果。
2、避免有不规则形状(图片)出现。识别工具在进行版面分析时,只能采用方形切割,当图片中存在文字环绕不规则形状时,则无法将文字和该形状划分开,则将出现错误或无法识别。此时,较快的办法是在PS中,吸取该图片附近的页面底色,用粗画笔将该区域涂上,不必讲求效果,颜色没有太大差别即可,重新保存图片。
3、避免图象倾斜。尚书七号中也有自动倾斜校正和手动倾斜校正工具,但即使经过校正,识别率还是低很多。如果是拍摄的书本,可能会产生一定弧度,此时保证行的两端对齐即可。另外在拍摄时应避免高光等会使图象各部分亮度反差大的情况。
4.为了得到较好的OCR使用效果,建议用户将扫描仪的驱动SCANWIZARD 5软件,由初始安装的标准控制面板,切换到高级控制面板状态。
文档识别
1. 过程与上面所介绍,基本一样,只是用户需要注意存盘格式。
2. 一般,如果用户需要对该文字,进行重新排版工作,请用户选择TXT存盘,然后再将其内容拷贝到WORD中。
3. 如果用户希望保留稿件的原有格式,并能够作版面的恢复,请使用RTF格式存盘,该格式将有版面的恢复功能。但是用户只能针对其中的文字,作一些个别字的调整,无法作大范围的排版方式的修改。
OCR识别
1. 其中,扫描、自动倾斜矫正过程同普通文稿是一样的。
2. 但是注意版面分析后,对其结果进行检查。应该在表格上,经过版面分析后,有一个兰色的框,选中了表格部分,如果不是,用户需要修改栏属性或者考虑手动划定识别区域。
3. 注意输出结果的选择,如果是需要重新排版,用户应该分别用TXT和XLS格式存盘,然后将TXT中的文字和XLS中的表格分别拷贝到WORD,进行排版。
转换技巧
1、可以将书摊平,一次将两边都扫描或拍摄下来,节省时间。处理图片时不必剪开,这时要用到尚书七号的分栏工具了。直接用鼠标在打开的图象上拖拽,可出现选框,分成左右两个分栏,分栏左上角的编号就是识别结果的排列顺序。它会将自动按照编号顺序将所有分栏的内容连接在一起。
2、手动分栏可解决部分图象无法识别的问题。在进行识别后,可以看到版面分析结果,有时候由于图象质量原因,自动分析出的有效版面只是很小的一部分。此时可以按ctrl+del取消版面分析结果,用鼠标拖拽,划定需要识别的范围,重新进行识别。当图片质量问题不大时,这个办法有效。
有时候(尤其是拍摄所得图片),文字扭曲严重,即使用PS也无法调整好。可尝试手动分栏,多划分几栏,每一栏包含一行或少数几行文字,这样对于每个分栏来说,它所包含的范围内误差度相对减小,可提高识别率。
3、使用批量识别功能。尚书七号可以一次性识别大量图片。但在实际应用中,依次识别不宜过多,便于随时检查识别结果,发现错误及时修正。
4、批量识别图象时,保存文件也要花费大量时间。事实上,尚书七号在识别文件的同时,会在图片所在文件夹生成文本文档,名称与图片名称相同。因此,如果不是特别需要,可以不必再保存输出结果。
如所识别内容属于一部分,可以将左侧的图象列表全选(ctrl+A),再选择输出--到指定格式文件则当前所有识别内容按照图片排列顺序保存在一个文件中。
我使用的尚书七号不能记忆保存路径,每次选择保存时,都会默认打开程序安装目录下的outout文件夹,不必每次都选择路径,可以先保存在这里,然后一起转移文件。
5、如果想保留文件中的图片,在输出结果时选用RTF格式,再用word打开,可以看到格式完全正确的文字和图片了。
6、用书本的页码给文件命名是明智的选择。我曾经用内容摘要命名,自以为清晰明了,结果在最后修正错误字符时悔恨交加。
7、当一个图象完全无法识别时,可稍稍增加亮度或对比度,有时候只差那么一点点,它也不给你工作。
8、分栏的几个类型。当单击一个分栏时,工具栏中会相应分栏类型的按纽会按下。分栏有横栏(横排文字)、竖栏(竖排文字)、图片、表格等几个类型,一般情况下可以自动识别类型,但手动分栏时一定要选择相应的类型,以提高识别率。
以上问题针对拍摄情况而言,扫描的话相信会减少问题,如果能拆书的话,最好还是拆吧。

mdb转换excel(xls/XLSX) 转换翻译1.32Mv1.2.0 官方版
下载
NTFS与FAT32转换器 转换翻译1.50Mv2.0 官方免费版
下载
火云译客翻译软件 转换翻译56.79Mv5.3.23.0 官方最新版
下载
word2007转换器 转换翻译5.59M完整版
下载
谷歌金山词霸合作版 转换翻译57.29Mv2.0 免费版
下载
hanvon pdf converter(汉王PDF转换软件) 转换翻译34.17Mv8.1.4 中文版
下载
雅信cat(英汉双向翻译软件) 转换翻译13.79Mv3.5 破解版
下载
晴窗中文大侠修改版 转换翻译7.58Mv6.0.9 加强版
下载
扫描件转换成word转换器 转换翻译44.41M官方最新版
下载
金山快译2007 转换翻译2KB绿色破解版
下载
Wondershare PDF Converter(PDF转换器) 转换翻译9.79Mv4.0.1.4 中文绿色破解版
下载
AnyBizSoft PDF Converter(PDF转换器) 转换翻译10.74M绿色汉化版
下载
文字转语音播音系统软件 转换翻译52.79Mv7.4 最新版
下载
SDL Trados Studio(翻译软件) 转换翻译394.00Mv2017 中文破解版
下载
金山快译个人版 转换翻译69.83Mv1.0 绿色完整版
下载
转换pdf格式文件(kdh转换成word) 转换翻译2.31Mv2017 最新版
下载








