
汉王pdf ocr简体中文版
v8.14.16 免费版大小:34.90M更新:2019-08-29 22:21
类别:转换翻译系统:Win7, WinAll
分类
大小:34.90M更新:2019-08-29 22:21
类别:转换翻译系统:Win7, WinAll
汉王pdf ocr简体中文版是一款非常实用的pdf工具,只需使用手机拍照,就能将图片上的文字直接转换为文本格式,方便快捷,让你能节省下时间去做更多的事!感兴趣的小伙伴快来体验吧!
汉王pdf ocr
支持文字型pdf的直接转换和图像型pdf的ocr识别,既可以采用ocr的方式,将pdf文件转换为可编辑文档,也可以采用格式转换的方式直接转换pdf文件为文本。汉王pdf ocr功能强大,非常实用,有需要的用户不妨下载试试看。
天若ocr文字识别工具:
你可以通过使用这款软件识别图片上的文字,操作简单便捷,你可以直接截图然后通过该软件进行文字识别,功能很强大

1、到当易网下载压缩包之后,解压打开,点击下一步
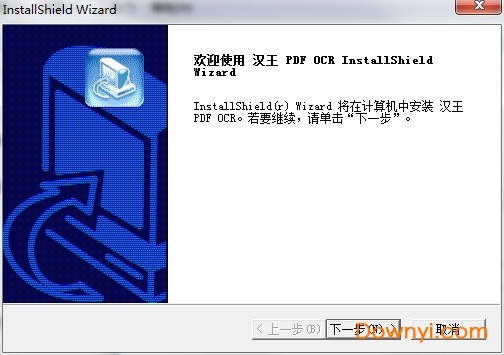
2、点击“是”然后等待软件安装完成即可
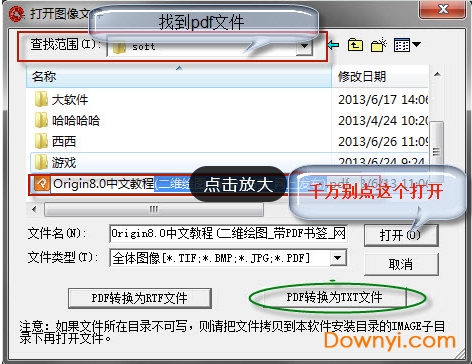
1、首先我们打开在电脑上安装好的汉王pdf ocr软件,然后就可以进入到软件的主界面,如下图所示,我们可以先点击文件选项,然后会出现下拉框,我们选择点击“打开图像”选项,你可以可以直接使用打开头像的快捷键,快捷键ctrl+o。

2、接下来我们就会进入到打开头像文件界面,如下图所示,我们需要找到你在电脑上的pdf文件,找到后我们点击pdf文件选中它,接下来点解界面下方的“pdf转换为txt文件”选项,然后进入下一步。这里需要注意的是不要点击界面中的“打开”选项。
3、然后我们就进入到pdf转换为txt界面,如下图所示,我们在界面上选择转换的页面,你可以选择转换的范围,从第几页开始到第几页结束,选择完成后我们在界面的下方还需要选择保存目录,点击浏览选择合适的位置后再点击确定。
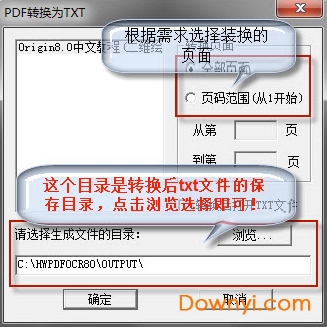
4、等待转换完成后,我们就可以在设置的保存位置找到转换完成后的txt文件了。转换的时间是根据你转换的数量来决定的,数量少,转换快,数量多,转换的就比较慢。
1.图像输入、图像前处理、预识别。
2.图像输入
汉王pdf ocr对于不同的图像格式,有着不同的存储格式,不同的压缩方式,目前有opencv、cximage等开源项目。
3.预处理
汉王ocr文字识别软件功能主要包括二值化,噪声去除,倾斜较正等。
4.二值化
对摄像头拍摄的图片,大多数是彩色图像,彩色图像所含信息量巨大,对于图片的内容,可以简单的分为前景与背景,为了让计算机更快的、更好地识别文字,我们需要先对彩色图进行处理,使图片只前景信息与背景信息,可以简单的定义前景信息为黑色,背景信息为白色,这就是二值化图。
5.噪声去除
对于不同的文档,对噪声的定义可以不同,根据噪声的特征进行去燥,就叫做噪声去除。
6.倾斜校正
由于一般用户,在拍照文档时,都比较随意,因此拍照出来的图片不可避免的产生倾斜,这就需要文字识别软件进行较正。
7.版面分析
汉王ocr文字识别软件可以将文档图片分段落,分行的过程就叫做版面分析,由于实际文档的多样性,复杂性,因此,目前还没有一个固定的,最优的切割模型。
8.字符切割
由于拍照条件的限制,经常造成字符粘连,断笔,因此极大限制了识别系统的性能。
9.字符识别
这一研究已经是很早的事情了,比较早有模板匹配,后来以特征提取为主,由于文字的位移,笔画的粗细,断笔,粘连,旋转等因素的影响,极大影响特征的提取的难度。
10.版面还原
人们希望识别后的文字,仍然像原文档图片那样排列着,段落不变,位置不变,顺序不变地输出到word文档、pdf文档等,这一过程就叫做版面还原。

11.后处理、校对
汉王pdf ocr根据特定的语言上下文的关系,对识别结果进行校正,就是后处理。
1.在开始菜单中打开ocr软件。
2.点击【文件】-【打开图像文件】,选择一副包含文字的图片。
3.点击【识别】-【开始识别】。
4.汉王ocr文字识别软件会识别出图片上的文字,可以对一些识别错误的字进行修改。
5.修改完成后点击【输出】-【到指定格式】,保存识别出来的文本。
6.可以打开保存的文本,将文本复制到word等软件处进行二次编辑。
1、在汉王pdf ocr主界面任务栏左上角【文件】选项中选择打开图像,快捷键ctrl+o。
2、查找您需要转换的pdf文件,注意:不需要点打开,你只需要选中就行,然后点击【pdf转换为txt文件】。
3、选择你需要转换的页面,也就是你pdf文件里边的内容你需要转换的部分,默认是全部转换。然后选择转换后txt文版的保存地址,点击【浏览】选择文件夹。
4、转换完成,时间根据内容的多少来确定。
扫描文件: 按下“ctrl+n”调出扫描程序,扫描图像文件。
打开文件: 按下“ctrl+o”打开图像文件,追加图像文件。
保存图像: 按下“ctrl+s”键保存图像。
图像反白: 按下“ctrl+i”将图像反白。
自动倾斜校正: 按下“ctrl+d”进行自动倾斜校正。
手动倾斜校正: 按下“ctrl+m”进行手动倾斜校正。
版面分析: 按下“f5”键,对选中的文件进行版面分析。
取消版面分析: 按下“ctrl+del”键,取消当前页的版面分析。
没有什么比照着打印出来的材料,再把字原样输入计算机更让人没有成就感。只需将材料扫描/用手机拍照,然后交给软件识别成文本。汉王 pdf ocr 提供 pdf 自动转换 rtf/txt 功能,汉王ocr文字识别软件同时支持 tiff/jpeg/gif 等图像格式文本识别。手动操作基本步骤是先调整角度,之后自动识别版面,f8 开始识别。
根据多次使用的经验,汉王pdf ocr 对纯中文/英文的情况处理准确率极高,但对同一行中英文混合的情况处理不理想。此外,汉王 pdf ocr个人用户可免费使用,不可商用。
光学字符识别(英语:optical character recognition, ocr)是指对文本资料的图像文件进行分析识别处理,获取文字及版面信息的过程。ocr的概念是在1929年由德国科学家tausheck最先提出来,并申请了专利。后来美国科学家handel也提出了利用技术对文字进行识别的想法。国内最早的ocr商业应用是由中国科学家王庆人教授在南开大学开发出来的,并在美国市场投入商业使用。
汉王pdf ocr是一款汉王和尚书七号升级版本,汉王pdf ocr也是一款文字处理软件。软件pdf文件的处理功能,可以把pdf文件去转化为可编辑的各种文档,还具有txt、rtf、htm等多种文字输出格式,以及版面还原功能。
对部分功能进行了优化
把pdf文件转换成txt不成功?
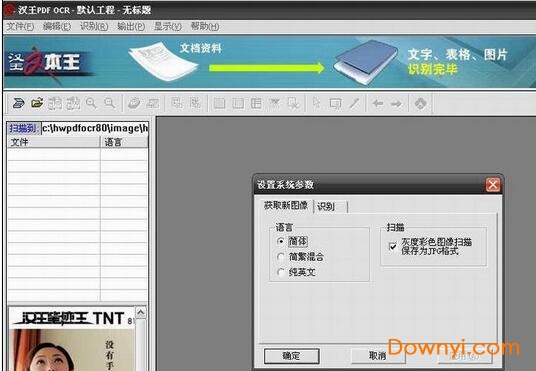
因你的pdf文件是图形格式,不能直接转换(转换了也是空白的),需要用ocr识别。识别前进行ocr识别设置,语言和灰度设置。
别的文字都是乱码?
1、可能是图片不清晰,扫描的时候调整一下分辨率。高级选项也可以设置一下大小。
软件可以识别英文吗?
1、可以,识别之前,在菜单或者工具栏里面设置一下是识别中文或英文。
晴窗中文大侠修改版 转换翻译7.58Mv6.0.9 加强版
下载
扫描件转换成word转换器 转换翻译44.41M官方最新版
下载
金山快译2007 转换翻译2KB绿色破解版
下载
Wondershare PDF Converter(PDF转换器) 转换翻译9.79Mv4.0.1.4 中文绿色破解版
下载
AnyBizSoft PDF Converter(PDF转换器) 转换翻译10.74M绿色汉化版
下载
文字转语音播音系统软件 转换翻译52.79Mv7.4 最新版
下载
SDL Trados Studio(翻译软件) 转换翻译394.00Mv2017 中文破解版
下载
金山快译个人版 转换翻译69.83Mv1.0 绿色完整版
下载
转换pdf格式文件(kdh转换成word) 转换翻译2.31Mv2017 最新版
下载
本地网络双用版文本转语音助手 转换翻译1024v1.0 最新绿色版
下载
580pdf转换成word软件 转换翻译12.16M
下载
汉王pdf word转换器 转换翻译34.90Mv8.1.4 官方免费版
下载
pdf creator中文版 转换翻译20.50M最新版
下载
得力pdf转word修改版 转换翻译10.12Mv1.81 最新版
下载
Solid Converter PDF中文修改版 转换翻译127.00Mv9.2.7478 简体安装版
下载
得力pdf转word(pdf转换软件) 转换翻译10.12Mv1.81 最新版
下载























2
回复湖南株洲客人
汉王pdf ocr识别文字真的超级方便,而且还可以保存为各种格式的文档